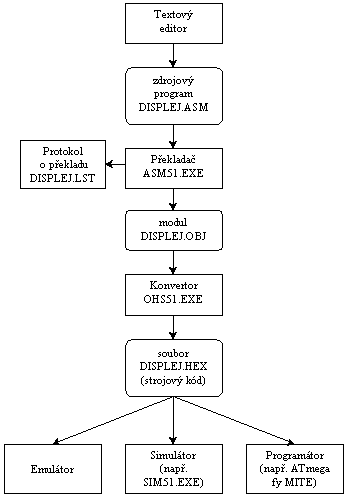
Když napíšete nějaký program pro 8051, je nutné jej přeložit a nahrát
jej programátorem do samotného mikroprocesoru. O způsobu nahrání programu do
mikroprocesoru a jiných alternativách odzkoušení napsaného programu jste se
mohli dočíst na stránce oživení procesoru. Na
této stránce se budeme zabývat tím, jak se ten nějaký program vlastně píše a co
se skrývá pod slovy "přeložení programu".
Při vývoji programu pro kterýkoliv
typ mikroprocesoru je třeba znát nejen jeho architekturu a možnosti jeho
instrukčního souboru, ale také možnosti programového vybavení, ve kterém budeme
program vytvářet. Programovým vybavením myslíme program nebo spíše několik
programů, které budeme mít uloženy v nějakém adresáři na osobním počítači PC a
pomocí nichž program pro 8051 napíšeme, přeložíme, třeba i odzkoušíme a nakonec
většinou i nahrajeme do mikroprocesoru. Vše bude vysvětleno dále.
Prvním krokem v procesu vývoje programu je jeho vymyšlení a
napsání. Vymyšlení bývá úkol nejtěžší. Programátor musí vědět co chce udělat a
jak to udělat. My se budeme bavit jen o samotném napsání programu. To, jakým
způsobem budeme program zapisovat, záleží na tom, jaký programovací jazyk si
zvolíme. Nejpoužívanějším jazykem je jazyk symbolických adres (zkr. JSA), někdy
nepřesně označovaný jako assembler. Assembler je totiž program, který převádí
zdrojový program napsaný v JSA na další stupeň v procesu překladu - viz dále.
Ono je totiž jednodušší říct: "...napsaný v assembleru" než "...napsaný v jazyce
symbolických adres".
Dále v textu budu namísto slova assembler používat slovo
překladač - záleží na vás, které slovo si více oblíbíte. Jazyk symbolických
adres má nejblíže strojovému kódu mikroprocesoru, při programování v něm
dosáhneme nejefektivnějšího programu - bude rychlý a paměťově nejméně náročný.
Jinou možností je využít některého vyššího programovacího jazyka jako je C,
Pascal nebo Basic. Pro programátora je vytváření programu v tomto jazyce
jednodušší, přehlednější, nemusí se učit nový jazyk, pokud již některý vyšší
prog. jazyk zná. Tento luxus je ale za cenu toho, že takovýto program bude o něco
pomalejší a paměťově neoptimalizovaný, než kdyby byl napsán v JSA. Jde o to, že
program napsaný v C nebo Pascalu musí být stejně přeložen do JSA automaticky
pomocí programu zvaného kompiler. "Inteligence" převodu do JSA je tak dána
vyspělostí daného kompileru a programátor ji sám obvykle nemůže nijak ovlivnit.
My se budeme dále bavit pouze o práci a psaní programů v JSA, psaní programů v C
nebo Pascalu se totiž provádí většinou v nějakém speciálním editoru, jehož
součástí bývá i daný kompiler. K úspěšné práci nám stačí i pouhý kompiler,
zdrojový program pak píšeme v běžném text. editoru (viz níže). Tady je dobré
poznamenat, že vývojová prostředí pro vyšší prog. jazyky (editor+kompiler+další
komponenty) jsou v naprosté většině nabízeny jako komerční placené produkty,
jejíž součástí bývá i dokumentace, mimojiné obsahující přesný postup práce.
Zdrojový program (tj. program zapsaný ve zvoleném program. jazyce, v našem
případě JSA) tedy napíšeme v nějakém textovém editoru, který do výsledného
souboru nepřidává své vlastní formátovací nebo řídící informace, lze tedy použít
např. Poznámkový blok z Windows 95/98/Me/NT/2000/XP, textový editor integrovaný
v Norton Commanderu atd. Můžeme použít i další programy jako WordPad nebo MS
Word všech verzí, výsledný dokument ale musíme uložit jako "čistý text", tj. v
případě WordPadu zvolit při ukládání typ souboru textový dokument - formát
MS-DOS, v případě MS Wordu zvolit typ souboru MS-DOS text nebo něco
podobného.
Druhý krokem je přeložení programu.
Máme tedy připravený zdrojový program (textový soubor) v JSA. Teď musíme využít
služeb některého z tzv. překladačů. Tento překladač zajistí kontrolu správnosti
zápisu zdrojového programu a jeho převod do souboru ve formátu jakéhosi modulu.
Vzniklý soubor bude mít příponu OBJ. Současně s ním se vytvoří i textový soubor
s příponou LST, což je protokol o průběhu překladu. Pokud byly při překladu
objeveny chyby (např. chyba syntaxe, duplicitní návěští apod.) - což překladač
po překladu zahlásí, jsou v tomto souboru v rámci výpisu zdroj. programu chyby
označeny a charakterizovány. Je zde dále možno nalézt další informace o programu
(tabulka symbolů, rozmístění v paměti atd.) Pravidla správného zápisu programu
budou popsána dále. Tady se musím
blíže zmínit o vytvořeném souboru s příponou OBJ, který je výše označen jako
modul a jež souvisí s tzv. modulární tvorbou programů.
Modulární programování může být výhodné při psaní rozsáhlých
programů - mohou práci zjednodušit a zpřehlednit. Jde o to, že si programátor
může zamýšlený program rozdělit do několika samostatných částí, které mohou do
jisté míry fungovat nezávisle na sobě. Bude psát např. program pro realizaci
mikroprocesorem řízeného voltmetru. Program si může rozdělit třeba na 3 části -
první bude řešit zpracování výstupů z A/D převodníku, druhá bude řešit obsluhu
displeje, třetí bude řešit snímání skupiny tlačítek. Jak je vidět, druhá a třetí
část by mohly mít univerzální použití i v jiných aplikacích (programech). Proto
si programátor všechny 3 části zapíše do 3 samostatných souborů (=modulů). Musí
pak vyřešit vzájemnou vazbu mezi moduly - tj. správné definování vstupů a
výstupů modulů a předávání dat mezi jednotlivými moduly. V našem případě je tedy
důležité nadefinovat vstupy u 2.modulu, výstupy u 3.modulu, a v 1.modulu
zajistit předání dat do 2.modulu a přijetí dat z 3.modulu. S jednotlivými moduly
se přitom pracuje stejně jako kdybychom měli jeden samostatný soubor (modul).
Programátor si tak může časem vytvořit celou knihovnu modulů, řešících dílčí
oblasti vyvíjených aplikací (knihovní moduly mají příponu OBJ nebo LIB).
Jak
z předchozího vyplývá, při definování v/v a předávání dat budeme potřebovat
nějaké další, speciální instrukce, kterými řekneme překladači, co má dělat.
Těmto instrukcím se říká pseudoinstrukce a představují tzv. direktivy
překladače. Protože tyto pseudoinstrukce nejsou řádnými intrukcemi
mikroprocesoru, při běhu programu se nevykonávají - plní svojí funkci pouze při
překladu zdroj.programu a říkají překladači, co má při překladu dělat.
Pseudoinstrukce se používají i k mnoha dalším činnostem, můžeme pomocí nich
dělat následující: přiřazovat symboly konkrétním objektům, inicializovat nebo
rezervovat paměťový prostor, ovládat čítač instrukcí (PC) atd. Podrobně budou
direktivy překladače popsány níže.
Pokračujeme-li v druhém kroku, máme tedy vyvořen soubor s příponou OBJ nebo
několik těchto souborů, v případě, že náš program sestává z několika modulů.
Pokud máme 1 soubor, můžeme rovnou přistoupit k přechodu na konečnou formu a tou
je soubor ve formátu HEX, což je i přípona vytvořeného souboru. Pokud máme
souborů (modulů) několik, je nutné je ještě pospojovat do jednoho výsledného
souboru pomocí programu, jemuž se říká linker. Jeho výstupem je jediných soubor
opět s příponou OBJ nebo ABS. Soubor s příponou HEX je již konečný formát, ve
kterém se program nahrává pomocí programátoru do samotného mikroprocesoru.
Můžete se setkat s několika druhy formátu HEX, definovaný různými firmami,
nejznámější jsou Intel-HEX a Motorola-HEX. Pro nás je důležitý formát Intel-HEX,
pokud konvertovací program z OBJ na HEX umožňuje volit mezi druhy, musí být
nastaven Intel-HEX. Když se podíváte nějakým ASCII prohlížem (např. z Windows
Commanderu nebo třeba i Poznámkovým blokem) na obsah vyvtořeného HEX souboru,
uvidíte , že soubor je tvořen několika řádky začínající dvojtečkou, za níž
následuje vždy několik čísel v 16-kové soustavě. Když budete chvilku bádat,
zjistíte, že lze z čísel vyčíst zapsaný program. Bližší popis by zabral spoustu
místa a pro většinu programátorů jsou tyto informace zbytečné, proto případné
zájemce odkazuji na jinou
stránku, kde je formát Intel-HEX řádně rozebrán. Ve stručném souhrnu lze
říci, že při překladu dochází k náhradě symbolických označení skutečnými objekty
a hodnotami, přiřazení skutečných adres návěštím atd. - program se jednoduše
řečeno převede do formy strojového kódu srozumitelného mikroprocesoru.
Třetím krokem je nahrání programu ve formátu
HEX do obslužného programu hardwarového programátoru a následné přehrátí do
samotného mikroprocesoru. Pokud k vývoji aplikací využíváte nějaký vývojový kit
(viz 1.bod dle této
stránky) , pravděpodobně nemusíte provádět překlad programu do HEX formátu
(je prováděn automaticky na pozadí vývoj.prostředí).
Celý proces vývoje programu je dobře vidět na následujících
obrázcích. Program, který je dle obrázku vlevo vytvářen, byl pro lepší ilustraci
pojmenován DISPLEJ.
Na obrázku vpravo je postup vývoje programu při
modulárním programování. Abych řekl pravdu, dosud jsem žádný program pomocí
dělení na moduly nenapsal, vždy jsem vystačil s jedním programem (modulem). Ve
vytvořené knihovně modulů může člověk časem ztratit přehled, pokud si ji řádně
nezdokumentuje. Ale to je věc názoru.
Programování v jazyce
symbolických adres
Co to je JSA?
Jazyk
symbolických adres (JSA) musí mít, tak jako každý programovací jazyk, určitá
pravidla zápisu a další obecné konvence platné pro daný procesor. Jak už z názvu
tohoto jazyka vyplývá, k popisu umístění jednotlivých instrukcí a jejich
operandů v paměti se neužívá konkrétních adres, ale pouze jejich symbolického
označení (návěští) a to navíc pouze ve vybraných - významných místech programu.
Každá instrukce programu musí být umístěna na přesně definovaném místě paměti
procesoru.
V průběhu vytváření programu ale stále dochází k mnoha změnám
(doplňování, přemísťování, vypouštění instrukcí), které by při absolutním
adresování každé instrukce znamenaly nutnost trvale přepisovat ovlivněné adresy
- což by byla nepředstavitelná dřina. Právě systém symbolů dovoluje
programátorovi nestarat se o detailní správu paměťového prostoru na úrovni každé
instrukce. To za něj automaticky provádí překladač, jemuž dává programátor
pokyny prostřednictvím již zmíněných pseudoinstrukcí a které překladači umožňují
orientaci v systému symbolických i reálných adres. Praktickým přínosem JSA je
to, že v celém zdrojovém programu označujeme symbolickými návěštími pouze
některé, zvlášť významné adresy. K takovým adresám patří začátek programu,
cílové adresy skoků a volání, vstupní body podprogramů atd. Zápis zdrojového
programu v JSA má určitý formát, který je částečně závislý na typu
mikroprocesoru, pro který program píšeme a také na vstupních požadavcích
překladače.
Formát zdrojového
programu JSA
Program v JSA zapisujeme po řádcích, kdy na jednom řádku
může být jen jedna instrukce nebo pseudoinstrukce. Každý řádek se může skládat
ze 4 částí, které je dobré od sebe pro lepší přehlednost oddělovat minimálně
jednou mezerou, lépe však několika mezerami nebo tabulátorem. Těmito čtyřmi
částmi jsou:
| 1 |
- návěští nebo symbolické
jméno |
| 2 |
- instrukce nebo pseudoinstrukce (mnemonická
zkratka) |
| Příklad pro instrukci |
 |
Příklad pro pseudoinstrukci |
| 1 |
2 |
3 |
4 |
| START: |
MOV |
A,P0 |
;text komentáře | |
|
| 1 |
2 |
3 |
4 |
| STOVKA |
EQU |
64H |
;text
komentáře | |
Jak je z
příkladů vidět, návěští se od symbolického jména odlišuje tím, že má nakonci
dvojtečku. Instrukce může mít 0 až 3 operandy, pseudoinstrukce má vždy alespoň 1
operand, případně výčet operandů (DB,DW).
Obecná
pravidla při zápisu programu
Symbolické
jméno musí začínat písmenem nebo speciálním znakem s výjimkou otazníku a
mezery. Jméno může tvořit teoreticky až 255 znaků, ale rozlišuje se pouze
prvních 31 znaků. Pokud se tedy v programu vyskytnou dvě dlouhá různá jména, ale
jež budou mít prvních 31 znaků stejné, překladač (assembler) zahlásí chybu.
Symbolická jména mohou být pouze před pseudoinstrukcemi přiřazení, tj. EQU, SET,
CODE, DATA, IDATA, XDATA, BIT a SEGMENT. Jako symbolická jména nemohou být
použity vyhrazené symboly, kterými jsou mnemonické zkratky instrukcí,
překladačem vyhrazené symboly (P0,A,B,R0,R1,TMOD,...), názvy direktiv
(pseudointrukcí). Objektmi, kterým se přidělují symbolická jména, bývají
překladačem vyhrazené symboly registrů (A,B,PSW,...) a bitů (C,F0,P1.1,...),
případně další symboly - $ aktuální stav čítače instrukcí (PC), @ nepřímá
adresa, # přímá data.
Návěští je též
symbol, který se od předchozího symb.jména odlišuje tím, že je ukončeno
dvojtečkou - např. START:
Jméno návěští se nesmí shodovat s již použitým
symbolickým jménem. Návěští může být umístěno na samostatném řádku, nejčastěji
se ale umísťuje před instrukci (na jednom řádku) a může být i před
pseudoinstrukcemi DS, DBIT, DB a DW. Návěští nesmí být v jednom programu
definováno vícenásobně - nemůže být několik návěští se stejným jménem, opět se i
zde rozlišuje prvních 31 znaků (max. 255 znaků včetně dvojtečky). Návěští může
obsahovat ze speciálních znaků pouze otazník a dolní podtržítko. Jako návěští
nemohou být použity vyhrazené symboly (stejně jako symbolických jmen). Hlavní
funkcí návěští je to, že fungují jako záložky určitých míst v programu, na které
se přechází pomocí instrukcí skoků/volání - tj.
xJMP,xCALL,JB,JNB,JC,JNC,JZ,JNZ,JBC,CJNE,DJNZ. S návěštím pracuje obdobně jako
se symbolickým jménem.
Operand - může jím
být konstanta (přímá data), přímá, nepřímá, relativní a bitová adresa, vyhrazený
symbol (registr nebo bit). Počet a typ operandů je dán použitím konkrétní
instrukce (viz instrukční soubor),
formát operandů u pseudointrukcí bude popsán dále. Tady si
ještě připomeneme, že konstanta (přímá data) vždy začíná znakem # a může být
zapsána v binární (např. 10101111B), hexadecimální (např. 0FFBCH) nebo dekadické
(např. 127D) soustavě. Typ soustavy označuje poslední znak v čísle - B, H a D. V
případě dekadické soustavy nemusí být znak D zapisován - stačí napsat jen např.
127. U hexadecimální soustavy je třeba mít na paměti, že konstanta musí vždy
začínat číslicí, tzn. že pokud konstanta začíná znakem A až F, je třeba před ní
napsat ještě 0.
Komentář je libovolný
informativní text, jehož začátek je uvozen středníkem. V komentáři, jak už název
napovídá, by se měl vyskytovat popis toho, co daná instrukce nebo část programu
provádí nebo k čemu vlastně daná část slouží. Komentáře je výhodné používat
proto, aby byl program srozumitelný a přehledný nejen pro samotného
programátora, ale např. i pro jeho spolupracovníky atd. a to i po delší době od
napsání programu. Zápis komentářů do programu samozřejmě není povinný. Maximální
délka komentáře je 255 znaků včetně středníku. Komentář může tvořit i samostatný
řádek programu, což se může hodit v případě, že je do programu nutné vložit
rozsáhlý komentář (nesmíme ale zapomenout napsat na začátek každého takového
řádku středník).
Jeden řádek programu může mít maximální délku 255
znaků. Co je napsáno nad, je překladačem ignorováno (překladač zahlásí chybu). Z
toho vyplývá, že výše uvedené maximální délky symb.jmen, návěští a komentářů
jsou reálné pro návěští a komentář, protože ty mohou být umístěny na samostatném
řádku. U symbolického jména vždy následuje pseudoinstrukce plus operand nebo
výčet operandů (výrazů), takže samotné symb.jméno nemůže mít nikdy celých 255
znaků.
Pseudoinstrukce překladače
(direktivy překladače) Co to jsou pseudoinstrukce a k čemu obecně
slouží jsme si popsali v předchozím textu. Nyní se podíváme na jednotlivé
pseudoinstrukce podrobněji a vysvětlíme si funkci těch nejpoužívanějších.
Podrobný popis, případně odlišnosti od zde uvedeného je nutné vyhledat v manuálu
ke konkrétnímu překladači, který budete používat. Naprostá většina zde uvedených
údajů by však měla být platná pro všechny překladače.
POZN: U formátu
pseudoinstrukcí platí, že výrazy v hranatých závorkách jsou nepovinné.
END
Začínáme od konce. Tato
pseudoinstrukce identifikuje konec zdrojového programu (textu) a ukončuje tak
práci překladače. Před touto pseudoinstrukcí nesmí být návěští ani symb. jméno,
může za ní být ještě komentář (na stejném řádku). Na dalším řádku programu by
již neměl být žádný další text, protože ten již překladač ignoruje (překladač
zahlásí chybu).
ORG
| 1 |
2 |
3 |
4 |
|
ORG |
výraz |
[;text komentáře] |
Tato
pseudoinstrukce nastavuje při překladu čítač instrukcí PC na hodnotu výrazu.
Není-li na začátku programu pseudoinstrukce ORG použita, potom překlad začíná
automaticky v programové části od adresy 0000H. Přesto je pro jistotu dobré na
začátku programu toto nastavení provést (zapsat ORG 0H). Před ORG nesmí být
návěští.
EQU
| 1 |
2 |
3 |
4 |
| Symbolické jméno |
EQU |
výraz |
[;text komentáře] |
Tato
pseudoinstrukce přiřazuje výraz ke zvolenému symb.jménu, kde výrazem mohou být
konstanta (#100H), konkrétní adresa (20H), vyhrazený symbol překladače
(R0,R1,...,A,B) nebo obecný výraz (ADR1+1). Programátor si tak jednoduše může
přejmenovat např. registr R0 na registr STOVKY a v programu pracovat s novým
jménem namísto původního R0 - např. MOV STOVKY,A).
BIT, DATA, IDATA, XDATA, CODE
| 1 |
2 |
3 |
4 |
| Symbolické jméno |
BIT |
výraz (bitová adresa) |
[;text komentáře] |
| Symbolické jméno |
DATA |
výraz (přímá 8-bitová vnitřní adresa) |
[;text komentáře] |
| Symbolické jméno |
IDATA |
výraz (nepřímá 8-bitová vnitřní adresa) |
[;text komentáře] |
| Symbolické jméno |
XDATA |
výraz (přímá 16-bitová vnější adresa) |
[;text komentáře] |
| Symbolické jméno |
CODE |
výraz (16-bitová adresa programové paměti) |
[;text komentáře] |
Tyto
pseudoinstrukce slouží k přiřazení konkrétní hodnoty nebo výrazu zvolenému
symbolickému jménu, kde konkrétního hodnota představuje adresu daného paměťového
prostoru dle typu pseudoinstrukce (uvedeného v závorce).
DB, DW
| 1 |
2 |
3 |
4 |
| [návěští:] |
DB |
konstanta nebo výčet konstant (8-bitů) |
[;text komentáře] |
| [návěští:] |
DW |
konstanta nebo výčet konstant (16-bitů) |
[;text komentáře] |
Tyto
pseudoinstrukce slouží k uchování konstant v programové paměti. Konstant může
být zapsáno i více, musí být od sebe odděleny čárkami. Konstantami mohou být
čísla, aritmetické výrazy, hodnoty symb.jmen a ASCII znaky. U DB jsou konstanty
8-bitové, u DW jsou 16-bitové. ASCII znaky musí být zapsány mezi uvozovkami.
Nejlépe bude ukázat si možnosti konstant na příkladech:
STOVKA EQU 100
DEFINICE: DB 127,13,54,0 ;čísla
DB 3*3,2*16 ;aritm.výrazy
DB STOVKA ;hodnoty symb.jmen (jsou-li definovány)
DB '(c) Copyright, 2001' ;ASCII znaky
DB 2*8,'MPG',2*16,'abc' ;je možné navzájem kombinovat
TISIC EQU 1000
DEFINICE: DW 12700,13,540,0 ;čísla
DW 3*328,2*165 ;aritm.výrazy
DW TISIC ;hodnoty symb.jmen (jsou-li definovány)
DW 'Co','py','ri','gh','t,',' 2','00','1' ;ASCII znaky
DW 3*328,'AB',2*16,'cd' ;je možné navzájem kombinovat
U pseudoinstrukce DW je narozdíl od DB možné do uvozovek zapsat
společně max. 2 ASCII znaky. První znak je umístěn ve vyšším bytu, druhý znak v
nižším bytu. Pokud je v uvozovkách zapsán jen 1 znak, do vyššího bytu
16-bitového slova budou zapsány nuly.
V případě, že použijeme před
pseudoinstrukcí DW návěští, bude návěští ukazovat na vyšší byte první zapsané
konstanty.
Všechny používané pseudoinstrukce (direktivy) jsou obsáhle
popsány v návodě k překladači firmy MetaLink Corp. (v souboru Asm_man.doc), o
kterém je řeč níže. Jsou zde popsány jak základní výše vyvsvětlené, tak i další
speciální pseudoinstrukce - pro práci s paměť. segmenty a registrovými bankami,
pro rezervaci paměti, pro práci s moduly atd.
Další odlišnosti překladačů
Překladače se mohou lišit v těchto několika důležitých věcech:
| |  | jaké pseudoinstrukce používají a znají |
| | | jaké vyhrazené symboly používají a znají |
| | | jaké typy procesorů podporují |
Dále se mohou lišit v tom, pro jaké
prostředí byly napsány (DOS-příkazový řádek, Windows 95/98), zda umožňují
upgrade na nové typy procesorů (přes konfigurační soubory) atd.
O
pseudoinstrukcích a jejich podpoře ze strany překladače už byla řeč v předchozím
textu. Podobně je tomu i u vyhrazených symbolů, čímž se myslí registry
A,B,R0,R1,SCON,TMOD atd. a bity RS0,RS1,F0,SMOD atd. Instrukce procesoru by měl
překladač znát všechny, poku jde opravdu o překladač pro daný typ procesoru -
tedy 8051. Jde ale především o registry a bity, jež jsou nyní součástí nových
klonů 8051 a které u původní verze 8051 nebyly. Nové klony mají integrovány
např. obvody watchdog, A/D převodník a nebo výstupní PWM obvody, jež se
obsluhují přes nově vytvořené registry, jež mají nějaké symbolické označení.
Stejně tak mohou u nových klonů přibýt nové vstupy/výstupy. Ty ale náš starý
překladač nezná, a proto jedinou možností je registry adresovat přímo, tj.
uvedením adresy.
Jsou i překladače, které dokonce neznají ani některé registry u
původní 8051, příkladem je registr PCON (87H). Ten nebyl u HMOSové verze
procesoru prakticky využíván (kromě bitu SMOD) a uplatnění získal až u verze
CMOSové. Proto ho některé starší překladače vůbec neznaly (podívejte se na poznámku). V takovém případě je dobré na začátku programu, který budete psát
a využívat v něm právě takové registry nebo bity, nadefinovat si je sám pomocí
pseudoinstrukcí EQU nebo BIT (např. PCON EQU 87H). Novější
překladače to totiž dělají podobně - v adresáři s překladačem bývá umístěn
textový konfigurační soubor, jež obsahuje definice registrů a významných bitů
určitého procesoru právě pomocí pseudoinstrukcí. Je pak možná jednoduchá
aktualizace překladače na nové klony původního procesoru.
Kde
sehnat překladač (assembler) a konvertor do HEX formátu? Pokud vám
stačí vyvíjet programy bez knihovny modulů, vystačíte s překladačem a HEX
konvertorem. Budete si ale muset zavzpomínat na práci v příkazové řádce DOSu.
Postup vývoje programu byl popsán a zakreslen výše. Množství
překladačů je možné najít na stránce http://www.programmersheaven.com/.
S konvertory do HEX formátu už je to horší.
Velmi dobrý překladač, který lze
na těchto stránkách najít, je Cross Assembler firmy Metalink Corp. Tvoří jej
program asm51.exe, konfigurační soubory a dokumentace. Překladač v sobě obsahuje
i konvertor do HEX formátu, takže nic víc nepotřebujete. Program je možné
stáhnout přímo i z mých stránek. Práce s
překladačem je dobře popsána v text.souboru asm_man.doc. Doporučuji si ho
pročíst, mohli byste být například překvapeni, proč překladač nezná symboly
některých bitů (Px.x atd.). Je totiž třeba na začátku každého programu
inicializovat konfig.soubor s definicemi symbolů pro daný procesor (podrobnosti
viz právě asm_man.doc - direktiva $mod).
Pokud chcete programy vyvíjet
modulárně (knihovna modulů), budete ještě navíc potřebovat spojovací program
(linker). Najít ale nějaký samostatný linker na internetu bude asi trochu
problém, bývá totiž většinou součástí nějakého komerčního (placeného) vývojového
kitu.
Ze všech zmíněných důvodů mohu proto jen doporučit, ať chcete
využívat knihoven modulů ano či ne, následující vývojové prostředí firmy Systronix. Je napsáno pro prostředí Windows
95/98, umožní vám pracovat s projekty (knihovny modulů), obsahuje překladač, HEX
konvertor i linker a hlavně je ZDARMA ke stažení! Program se jmenuje RAD51, nemá
žádná omezení, instaluje se jako standardní windowsová aplikace. Nemusíte znát
práci v příkazové řádce, napíšete program v integrovaném editoru, jedním
tlačítkem spustíte překlad a RAD51 vám do určeného adresáře vytvoří rovnou HEX
soubor. Vytvoří se i LST soubor, který ale bohužel neobsahuje protokol o průběhu
překladu, ani informace o případných chybách. Je proto nutné mít v RADu51
zapnuto okno Output (v menu View), v němž se hlášení o chybách překladu
zobrazují. Poslední verzi programu RAD51 je možné stáhnout ze stránek výrobce zde. Najdete jej i na
cédéčku HW CD2 v sekci
X51-SW pomůcky, jež vydal HW Server.
Jestliže chcete programy vyvíjet ve vyšším programovacím jazyce - C,
Pascalu nebo Basicu, opět doporučuji podívat se na stránku http://www.programmersheaven.com/,
kde je možné najít spoustu kompilerů pro daný jazyk. Kompilery je také možné
najít i HW CD2.
 |
© DH servis 2002 - |